iServDB is a kind of NewSQL database system
本資料庫團隊(資策會創研所)自民國101起,開始執行經濟部技術處所支持的「工業基礎技術研究計畫」[34]負責其「分散式資料庫技術」之研發,目前使用「iServDB」( http://iservdb.cloudopenlab.org.tw/ )[35]作為產品名稱對外推廣。iServDB之產品目標以適應國內產業需求為主,並整合國內產學技術供應鏈,形成自主技術良好的生態發展。
iServDB技術上的期待是能兼顧穩定發展與高度彈性,所以經綜合評估後,採PostgreSQL作為主要的技術載具,一則為開源發展的PostgreSQL有利於學習世界領先之資料庫技術;另一則為在國內資料庫產業相對疲弱之際,乘其之勢,縮短資料庫產業生態系與國際市場之差距。於穩定發展的面向,iServDB強化自動佈署、即時監控、相互備援、效率介面等與營運管理有關的項目;而高度彈性則研發了分散式資料庫技術,增強資料庫動態配置的能力,並延伸PostgreSQL foreign data wrapper機制,連結NoSQL類資料庫,如MongoDB[36]、Elasticsearch等,這與Multi-model database的設計類似,使多樣化的資料處理,能在單一SQL介面、單一資料庫系統中輕鬆完成。

圖2. 分散式資料庫技術系統架構圖
如前文所述,現今的資料庫系統已無法以一擋百,必須選擇好所面對的資料市場,而iServDB選擇的是資料分析的應用。再進一步來說,iServDB所設定的使用者為資料分析人員。由於資料分析行為的特性,它必須針對每一個案例進行微調其查詢行為,與傳統資料探勘行為常見的批次運算模式並不相同。故iServDB企圖發展一套能與資料分析人員快速互動的Interactive system,所以於技術上就必須擁有Bounded response time的系統。類似相關的技術目前由U.C. Berkeley與M.I.T.的聯合實驗室研發的BlinkDB[37],即進行此特性系統的領導性研究,專注於數值性資料的研究。
iServDB基於工業基礎技術研究計畫所要求的高技術挑戰性,挑戰過去只應用在數值上的抽樣統計方法,意即我們可能在人力物力無法完全計算之時,可利用已計算的結果,推估最終可能的數值範圍,常見於民意調查活動。與民意調查的情況相同,現在我們想要觀測的資料量已大到無法完全計算的程度了,單純數值統計是如此,還有更多複雜的非結構化資料在等著我們。
以iServDB所研發的高精確型Association rule系統方法為例,這類的資料分析方法不同於數值統計方法單純,典型的困擾即是資料運算時間不容易估計,使得分析決策的時效性也難以確保。而Bounded response time的研究即是限制其回應時間,不論運算量有多大,重點在於可預估其正確率,如此即可在決策的時效性取得平衡點。依本研究實驗結果,1分鐘內即可達到7成的正確率,並且每段時間都能不斷更新結果,而不一定要忍受無法估計的等待。
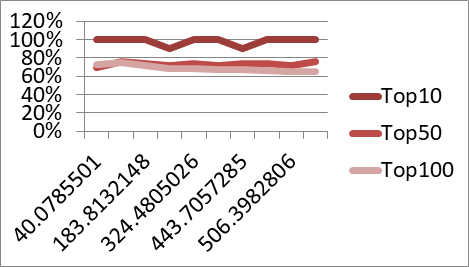
圖3. 實驗結果摘要圖
上圖橫軸為執行時間,縱軸為執行結果與傳統結果的比較後的準確率。由於分析應用通常只在乎排序最前端的結果,並不追求完全正確的清單(可能高達數千項,依support設定而有所不同),所以區分為Top10(前10項結果比較)、Top50、Top100等項目呈現。此研發實驗主要目標為突顯出,資料的計算在回應時間上是可以有彈性的,而典型的Association rule運算僅有「完成」與「未完成」兩極化的結果,它可以和既有完整運算的演算法互補,重點在於符合應用的需求,讓資料需求來領導資料運算。
另外,iServDB也投入Time series運算的研發,其相對應的應用為IOT,此類問題資料內容單純卻量大,但其關鍵在於大量的時序資料查詢,不同時間顆粒的重覆查詢也不斷改變,時常造成大量負載。iServDB研發可分散式且輕量化的時間序列索引機制,能分散處理,並大量縮減資料運算量,以Bounded response time的理念,確保隨時可回應的狀態,並逐步趨近理想值。此研發佈局未來,已申請台灣專利[38]及美國專利[39]並且獲證。
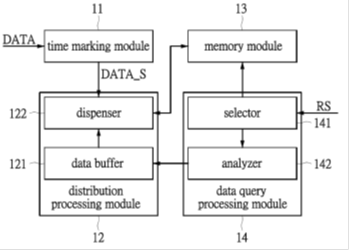
圖4. Time series專利示意圖
iServDB瞭解到世界脈動是瞬息萬變,資料本身也是越來越多樣化,所以除了SQL介面仍然保留之外,其他部份都採高彈性化設計,模組化可隨意組合。如NewSQL的思維一般,依應用選擇資料庫的功能,既保留SQL的介面也享受NoSQL的高效能。